About AI GameStore
Scalable open-ended evaluation of machine general intelligence with human games
How do we measure general intelligence in machines?
Rigorously evaluating machine intelligence against the broad spectrum of human general intelligence has become increasingly important and challenging in this era of rapid technological advance. Conventional AI benchmarks assess only narrow capabilities in a limited range of human activity. Most are also static, quickly saturating as developers explicitly or implicitly optimize for them.
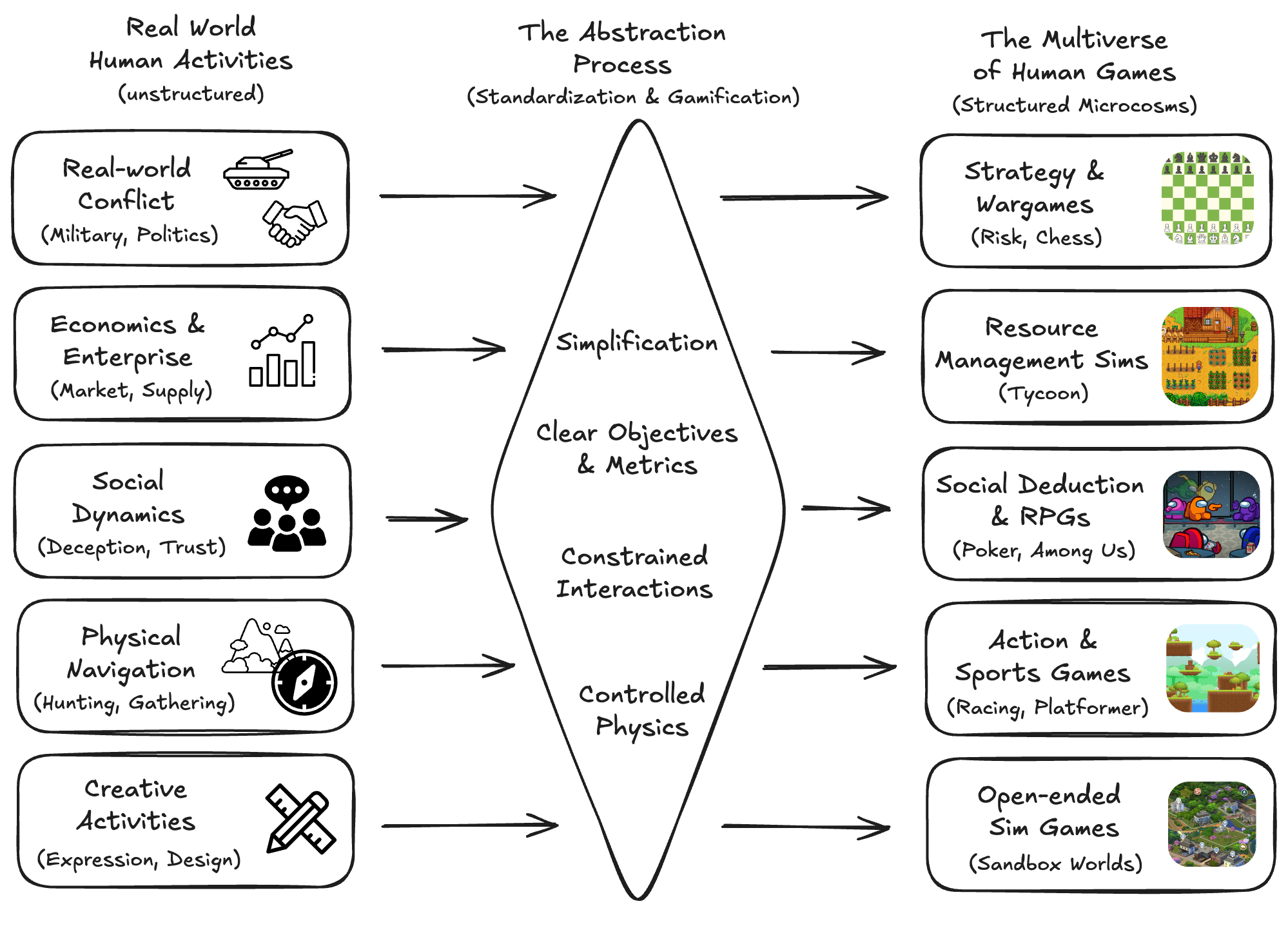
We propose that a more promising way to evaluate human-like general intelligence in AI systems is through a particularly strong form of general game playing: studying how and how well they play and learn to play all conceivable human games, in comparison to human players with the same level of experience, time, or other resources. We define a “human game” to be a game designed by humans for humans, and argue for the evaluative suitability of this space of all such games people can imagine and enjoy — the “Multiverse of Human Games”.
Why is it a good measure of general intelligence?
The proposition that the set of all conceivable human games serves as a robust proxy for human-like general intelligence is rooted in the teleology of play itself: humans design, engage in, and propagate games to prepare themselves for the multifaceted challenges that they are likely to encounter in dynamic environments and habitats.
Games are not merely pastimes but are sophisticated vehicles for cultural transmission. By abstracting and containerizing real-world complexities — ranging from the strategic planning in multi-party conflicts to the nuanced social dynamics of RPG games — humanity has collectively created a curriculum for training and preparing individuals for surviving and adapting in the open world. Games often pass down through generations and spread across cultures: invented thousands of years ago, Go and Chess are still enjoyed by millions of players today; the Olympic Games, which first emerged from the cradle of ancient Greek civilization, have evolved into a grand cross-cultural human enterprise with events practiced and watched by people around the world.
Consequently, the space of all conceivable human games represents a distilled, concentrated library of the essential skills required to navigate the world that humans live in. To master this space is, by design, to exhibit the core tenets of human-like general intelligence.
Challenges with using existing games
However, directly using existing games can face a lot of challenges:
- Copyright and licensing restrictions: The majority of commercial games are protected by proprietary licenses and intellectual property (IP) laws, preventing their use in public AI benchmarks without complex, costly, and often unattainable agreements with developers and publishers.
- Platform heterogeneity: Games are built on diverse engines (Unity, Unreal, custom), operating systems, and APIs. Creating a single, universal evaluation platform or standardized interface capable of normalizing input and state across thousands of structurally varied titles is a formidable software engineering challenge.
- Latency for real-time games: Many games on gaming platforms require rapid player response (e.g. action games with live combats). Today’s commercially available AI models, especially with thinking enabled, all have long latency for each API call. The model would trivially fail at these games if they are queried to play the existing real-time games as is.
- Human data collection and privacy: Obtaining high-quality human gameplay data for evaluating models is restricted by user privacy regulations (EULAs) and the unwillingness of game companies to share data logs.
- Dataset contamination risk: Because AI model developers frequently do not disclose their training data, it is impossible to verify which games in the benchmark have already been seen by the model. Model developers can also train their models on a vast space of digital games to perform well on such a benchmark that consists of actual games on digital gaming platforms. This risk of data contamination invalidates the evaluation as a measure of general intelligence.
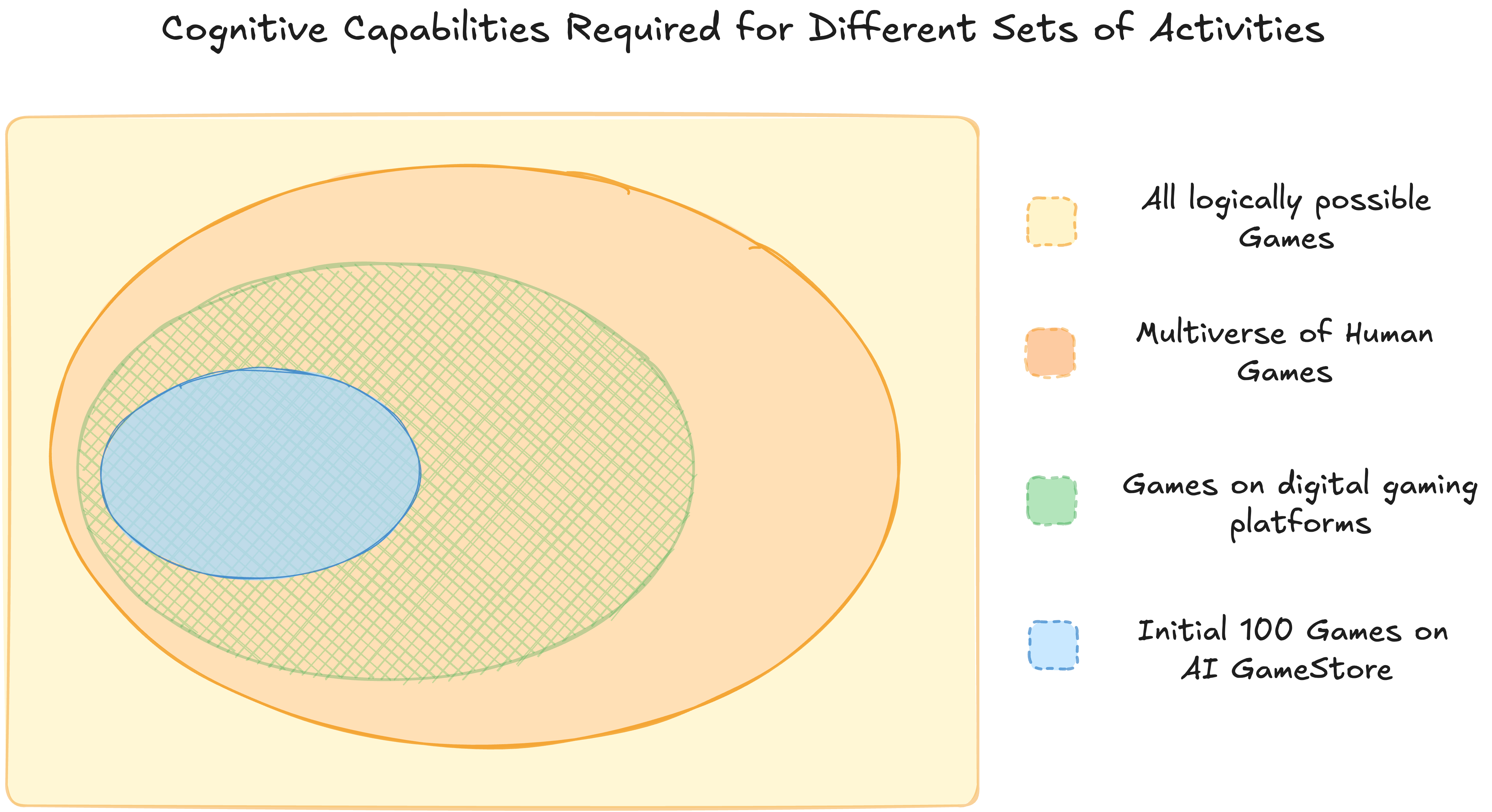
AI GameStore
We propose an alternative approach towards this vision by developing the AI GameStore. The AI GameStore is designed as a meta-benchmark for evaluating AI systems on a diverse set of human-designed games and to facilitate their comparison against human performance. However, instead of using the original set of games on gaming platforms, it uses a sophisticated automated pipeline to source and standardize games into standardized versions for benchmarking AI models.
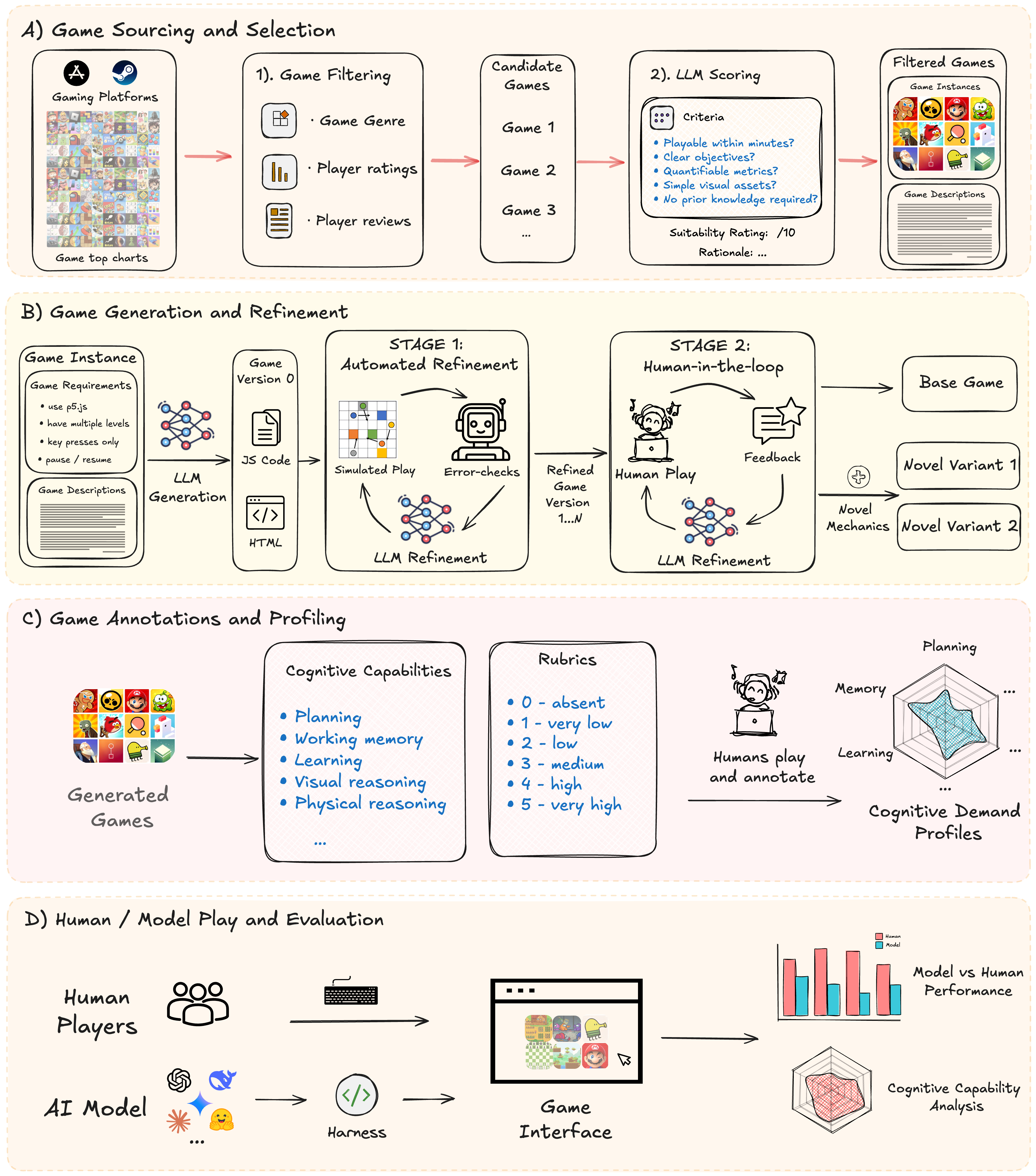
The pipeline
This pipeline operates across four distinct stages:
- Stage 1: Sourcing and suitability filtering. High-quality game candidates are harvested from existing gaming platforms and subjected to a multi-stage filter based on player engagement metrics and an LLM-driven suitability scoring system.
- Stage 2: Game generation and refinement. Utilizing filtered game descriptions, an LLM generates a functional p5.js codebase. This draft undergoes automated unit testing via simulated play to ensure mechanical stability and basic responsiveness to input. The functional code is subjected to a secondary refinement phase where human participants provide natural language feedback to correct mechanical issues, increase playability, and propose novel gameplay variations.
- Stage 3: Game annotation and profiling. To characterize the latent cognitive demands of the benchmark, each finalized game is subjected to a human annotation process. Expert annotators evaluate the tasks across a multi-dimensional cognitive taxonomy using a 0–5 scale. These profiles allow for the disentanglement of complex model behaviors by mapping performance failures to specific cognitive demands, ensuring that the AI GameStore serves as both a benchmark and a diagnostic tool for understanding machine intelligence.
- Stage 4: Model evaluation. In the final stage, both human players and various AI models interact with the games through a gameplay interface. AI models are integrated via a specialized harness to ensure standardized interaction. The resulting game output is used to compute aggregate human vs. model performance as well as deeper analysis on the model’s cognitive capabilities.
In its current state, the AI GameStore is still very primitive. We anticipate that increasingly powerful agentic AI architectures will soon close many of the capability gaps we identified. We are actively extending the platform in several directions—in particular, by synthesizing harder games with longer play sessions (some requiring hours to complete) and by introducing more capable, human-like opponents.
While our current platform is only a modest beginning towards operationalizing the full “multiverse of human games” vision, we hope it serves as an example and a catalyst for building more general, scalable, open-ended AI model evaluations — and a small step towards the development of general-purpose agents capable of interacting intuitively and flexibly, and safely and robustly, with human beings in a human world.